
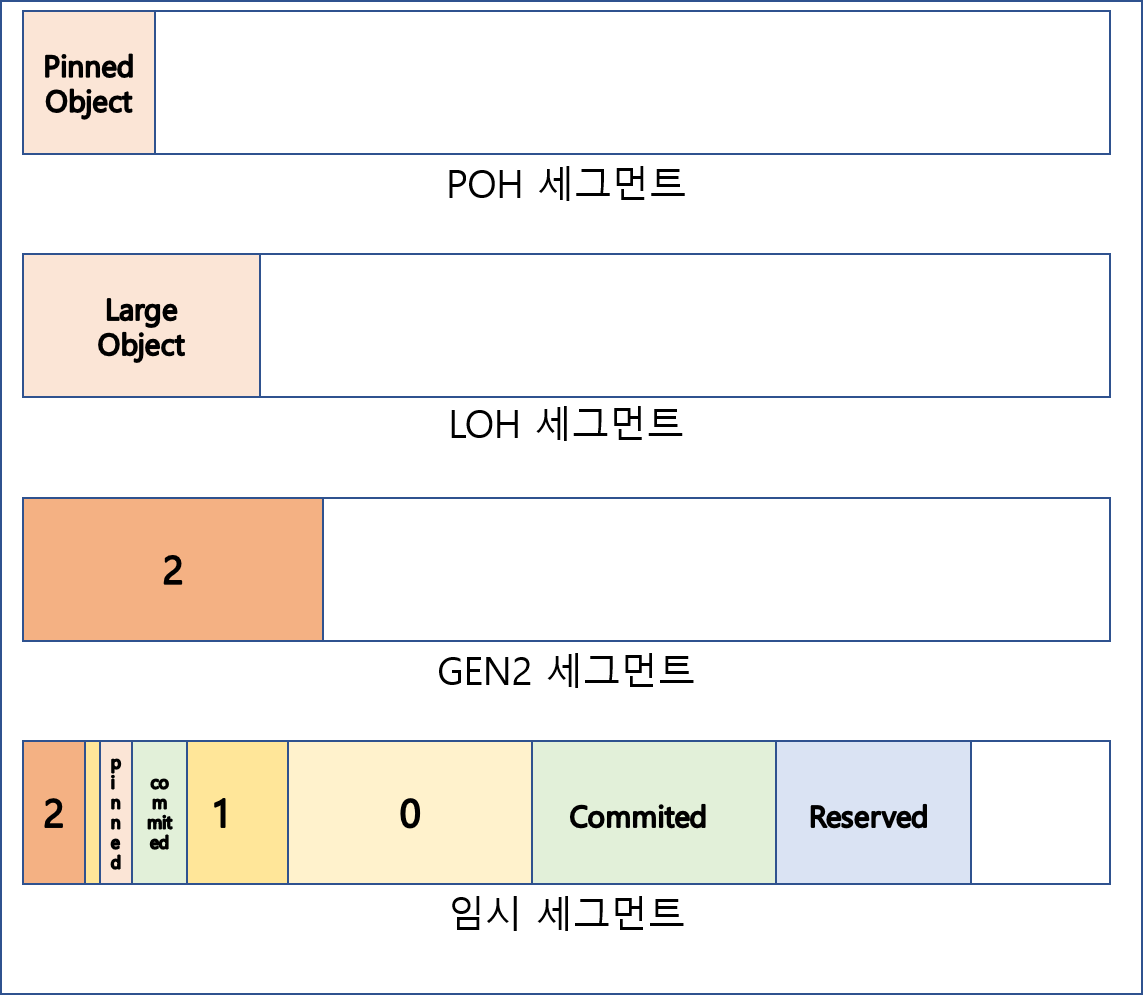
.NET GC 정리(2) 인터넷 여기저기 흩어져있는 GC 관련정보 정리 2탄. 틀린게 있다면 말해주세요. GCHeapAffinize SGC (Server GC)는 논리 코어갯수만큼의 힙을 가지고 있고 멀티코어에서는 병렬처리가 가능하기때문에 WGC (WorkStation GC) 보다 처리량이 월등하다. Heap Affinize는 힙과 코어를...
Posts
Cancel.NET GC 정리(2)
.NET GC 정리(1)
.NET GC 정리(1) 인터넷 여기저기 흩어져있는 GC 관련정보 정리 1탄. 틀린게 있다면 말해주세요. 누구나 아는 내용 다음은 누구나 아는 내용이고 .NET 버전이 달라져도 동일한 내용 (.NET 7까지는..) CLR이 제공하는 메모리 수집 기능 GC C#, ASP.NET 등 .NET 환경에서 개발한 프로그램은 CL...

몬테카를로 트리 탐색 - Monte-carlo Tree Search (MCTS)
[인공지능] MCTS 알파고에서도 사용된 탐색 알고리즘으로, 시뮬레이션을 통해 가능성이 높은 선택을 하며 탐색하는 알고리즘. 4가지 과정을 통해 진행된다. 선택(Selection) : 현재 주어진 트리에서 트리 정책(Tree Policy, 최선의 자식 노드를 선택하는 정책)에 따라 결정되는 최선의 ...
기계학습 - Machine Learning
[인공지능] 기계학습 컴퓨터가 스스로 학습할 수 있는 알고리즘과 기술을 개발하는 인공지능의 한 분야. 개발자가 직접 작성하는 기존의 프로그래밍은 많은 규칙을 직접 만들기에는 한계가 있다. (e.g. 스팸 메세지 필터링, 자율 주행 자동차) 기계학습은 다음과 같이 나누어진다. ...

역 강화학습 - Inverse Reinforcement Learning
[인공지능] 역강화학습 모방학습을 먼저 보고 오시면 좋습니다 ! 참고자료: [IRL 논문 1][http://ai.stanford.edu/~ang/papers/icml00-irl.pdf]1 , IRL 논문 22, RLkorea 논문 리뷰, PR-029 리뷰 영상 역강화학습이란 에이전트의 보상(Reward...

모방학습 - Imitation Learning
[인공지능] 모방학습 모방학습이란 전문가의 행동을 모방하며 학습하는 알고리즘. 모방학습에는 행동 복제(Behavioral Cloning)와 역강화학습(IRL, Inverse Reinforcement Learning)이 있다. 행동 복제(Behavioral Cloning) 전문가의 행동 데이터셋 (St ...
강화학습 - Reinforcement Learning(6)
[인공지능] 딥살사와 폴리시 그레이디언트 딥살사 (Deep SALSA) 기존에 살사 알고리즘으로 해결하기 어려운 문제를 심층신경망을 통해 해결하는 알고리즘. 문제 해결을 위해 MDP를 정하고 학습을 위해, 다음 수식과 같이 예측, 정답을 찾아내고 \[예측 : Q(S_t, A_t)\] \[정답 : R_{t+1...

강화학습 - Reinforcement Learning(5)
[인공지능] 인공신경망(Artificial Neural Network)과 강화학습 기존 강화학습의 한계 몬테카를로, 살사, 큐러닝은 모델 프리(Model-Free) 알고리즘으로 환경에 대한 모델 없이 샘플링을 통해 학습함으로써 다이내믹 프로그래밍의 한계 중 환경에 대한 완벽한 정보가 필요함을 해결하였다. 하지만 계산 복...
강화학습 - Reinforcement Learning(4)
[인공지능] 큐 러닝 (Q-Learning)과 전통적 강화학습 강화학습의 예측과 제어 강화학습은 환경의 모델없이 환경과의 상호 작용을 통해 최적 정책을 학습한다. 상호작용을 통해 정책에 대한 참 가치함수를 학습하는 것을 예측이라고 하며 예측과 함께 정책을 발전 시켜 최적 정책을 학습하는 것을 제어라고 한다. 몬...
강화학습 - Reinforcement Learning(3)
[인공지능] 다이내믹 프로그래밍 순차적 행동 결정 문제 풀이법 순차적 행동 결정 문제를 MDP로 정의 가치함수를 벨만 방정식을 통해 반복 계산 최적 가치함수 / 최적 정책 찾기 벨만 ...